DocuQuery: Document Intelligence Platform with Advanced RAG Architecture
Client
Philippine
Industry
IT/BPO
Project Duration
1 months
Team Size
2 members
langchain
Chroma DB
Gemini 2.0 Flash
Flask
Objectives
Our client is a prominent name in the IT/BPO industry. They sought help from X-Byte to build a software solution that could extract and analyze information from vast document repositories. The client aspired to build a comprehensive document intelligence platform that could transform unstructured PDF documents into searchable, actionable intelligence.
X-Byte, with its core competencies in AI-powered document processing and RAG (retrieval-augmented generation) solutions, developed a powerful document intelligence platform–DocuQuery that intelligently handles both text-based and scanned PDFs, providing accurate answers to complex queries through an advanced AI pipeline.
X-Byte’s advanced RAG architecture experts and AI/ML developers clearly defined the objectives:
- To develop an advanced document intelligence platform with retrieval-augmented generation (RAG) architecture for precise text extraction & document analysis.
- To utilize X-Byte’s expertise in multimodal document processing to create a system that handles both text-based and scanned PDF documents
- To design an intelligent text extraction system with OCR fallback capabilities
- To code a high-performance system that processes diverse document formats & seamlessly switches between extraction methods.
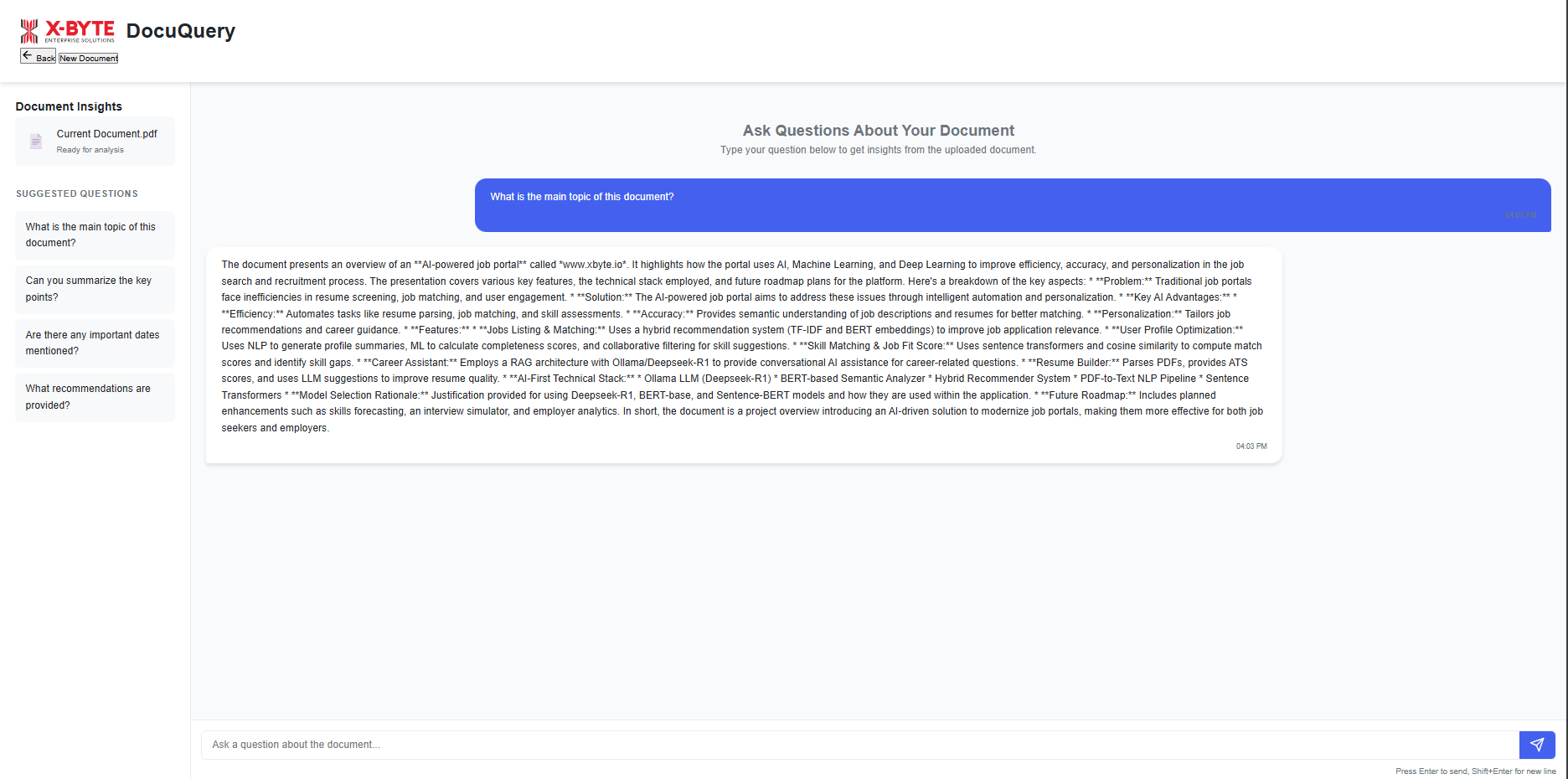
- To create a platform where users can query complex documents and receive accurate, contextually relevant answers
Challenges
Previously, the client identified inefficient document review processes that relied on manual reading and keyword searches. This created several significant challenges:
- Traditional document systems couldn’t process both native and scanned PDFs effectively
- There was no automated system for extracting relevant information from lengthy documents
- Employees spent excessive time searching through contracts, reports, and regulatory documents
- Without AI assistance, contextual understanding of complex document language was limited
- There was no proper tool to transform document repositories into interactive knowledge bases
X-Byte’s specialized expertise in document processing platform development and advanced RAG architecture helped the client overcome all the above challenges.
Approach and Solution
Requirement Analysis: X-Byte has been providing RAG as a service to its clients for a long time, and owing to our experience, we have developed SOPs that begin with a comprehensive analysis of client pain points and solution needs. After a thorough analysis of our client’s document processing needs and critical issues affecting them during document review and information extraction, our document intelligence experts determined that a hybrid processing approach with an advanced RAG pipeline would provide the optimal solution.
X-Byte developers designed a document intelligence platform with the following functionalities:
- Native PDF text extraction using pdfplumber
- Intelligent text splitting (8k tokens with 200 overlap)
- Hybrid document processing and contextual retrieval
- Advanced RAG pipeline with semantic understanding
- Multi-model support with Gemini 2.0 flash integration
- all-MiniLM-L6-v2 embeddings for semantic search
- Enterprise-grade architecture with secure deployment options
X-Byte Developed a Robust Document Intelligence Platform – DocuQuery
We developed the DocuQuery platform, where the document processing component intelligently handles both text-based and scanned PDFs. The system uses native PDF text extraction with pdfplumber for digital documents and automatically falls back to Tesseract OCR for scanned materials.
The advanced RAG pipeline optimizes text chunking with 8k tokens and 200 token overlap for maximum context retention.
X-Byte’s development team integrated a comprehensive vector embedding system using all-MiniLM-L6-v2 for semantic search capabilities. The key focus was on extraction speed and accuracy, especially when handling complex documents across industries like legal (contracts analysis, clause extraction), finance (annual report & financial document analysis), and academia (research).
We developed a system that allowed users to:
- Process diverse document formats with an automatic extraction method selection
- Query documents using natural language
- Receive contextually relevant answers drawn from the top 3 most relevant chunks
- Leverage Gemini 2.0 Flash integration for high-quality, accurate responses
- Deploy the solution securely within their existing infrastructure
Technology Stack
langchain
Chroma DB
Gemini 2.0 Flash
Flask
X-Byte’s technological expertise was showcased through our strategic selection of tech stacks for RAG as a service implementation.
Component and Technology Used:
Document Processing: pdfplumber + pytesseract OCR for hybrid document processing
Text Splitting: LangChain RecursiveCharacterTextSplitter for intelligent document chunking
Vector Database: Chroma DB Vector Store for efficient document indexing and retrieval
Embeddings Model: all-MiniLM-L6-v2 embeddings model for semantic understanding
LLM Integration: Gemini 2.0 Flash for advanced reasoning capabilities
API Framework: Flask REST API framework for robust service delivery
Results Achieved
The DocuQuery platform, developed by X-Byte for our esteemed client, eliminated the inefficiencies present in traditional document review. The manual document analysis process was replaced with a smarter, high-precision, faster, and high-scale platform that now transforms complex documents into interactive knowledge sources.
Overall, the client achieved quantifiable positive results:
- Document review time reduced by 75% on average
- Information extraction accuracy improved to 95-99% compared to 65-70% with manual methods.
- Query response time decreased to under 3 seconds for most document repositories.
- ROI achieved within 4 months through improved productivity and information access
X-Byte’s expertise in document processing technologies helped our client in pioneering key improvements in enterprise document analysis. Our ML development’s core strengths were reflected in the document intelligence platform development.
If you are looking for solutions with advanced text processing, multimodal document handling, and cutting-edge RAG architecture implementation, then reach out to the experts at X-Byte. We can be your trusted RAG development partner.